问题现象
从监控系统中发现系统节点状态异常,从后台的日志中查看日志如下
1 | throwable: |
OOM原因
A服务的接口 /plan/module 查询条件设置错误,导致查询出了数据库将近10w的订单数据,进而导致内存耗尽。在一次回收垃圾中
解决方案
- 修正逻辑错误,每次仅查一条订单数据
- 在查询服务中限制查询最大查询数据量,最大仅可查询10条数据。
问题定位过程
Q1:为什么op22在阿里云 kubernetes集群状态下是异常
由于check-health.do 接口无响应导致
Q2. 为什么check-health.do 接口无响应?
在日志中找到了答案,是因为服务OOM
1 | 2024-11-15 16:18:51,487 ERROR [DubboServerHandler-10.112.8.247:21885-thread-191] [com.iplatform.common.interceptor.GlobalResponseInterceptor] 7529e43823a147e08636c85d0968c43a - 业务执行出现未知异常: |
当Java虚拟机(JVM)花费过多时间进行垃圾回收但未能释放足够的内存时,就会出现这个问题,这通常表明你的应用程序内存不足。
Q3. 为什么通过ES日志无法获取到异常OOM
服务未将此异常上报
Q4. 知道了服务OOM,排查起来页简单,直接dump就可以,但是dump 下来的文件只有不到200M,为什么只有不到200M呢?
现在在已经得知问题的根本原因的情况去反推的话,在dump 之前服务已经做了full GC。GC之后能回收数据应该不是泄漏了
Q5. 既然推测不是泄漏了,那么修改jvm 的最大内存 从1G改到2G,再观察,虽然不再出现OOM,但是内存占用仍然会达到80%,这个服务是没什么流量的,不应该占用如此大的流量,拉dump,分析dump 支配树即,观察下图的dump发现支配树的内存总共也就占100M有余,但是整个dump 有1.4G,所以直接分析支配书应该分析不出来,那只能尝试分析对象实例了。
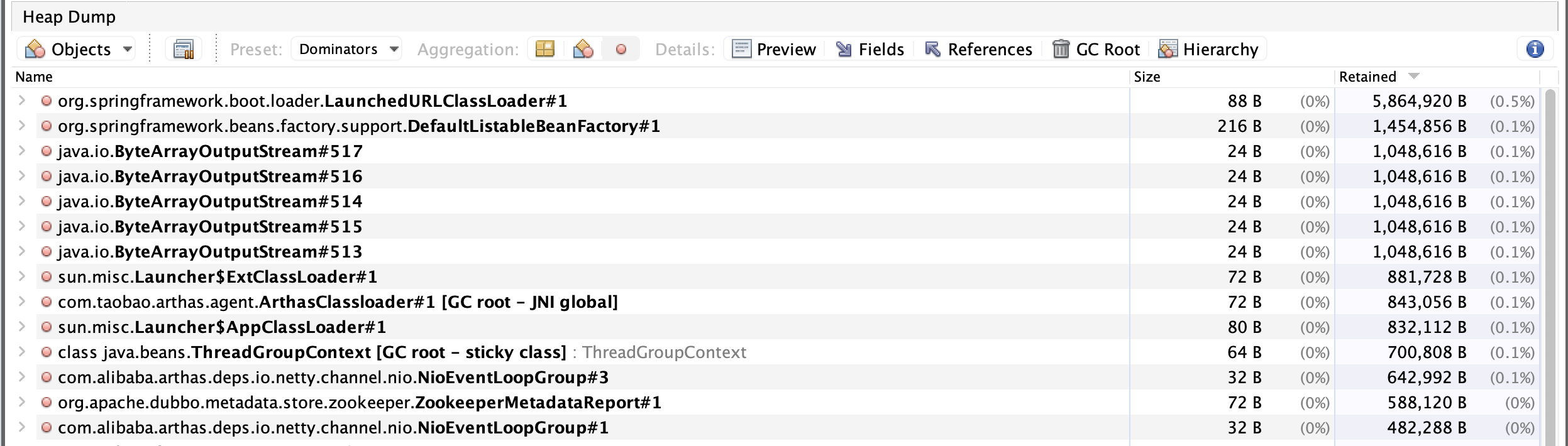
Q6:对象的实例倒是很明显,大对象特别多,其中有个一个对象竟然140M,饭解析一下这个对象,其内容如下,从140M的对象可以看出这是个特别大的字符串,而且这个字符串对象在序列化前和ResponseInfo以及OrderBillSimpleDto 有关系
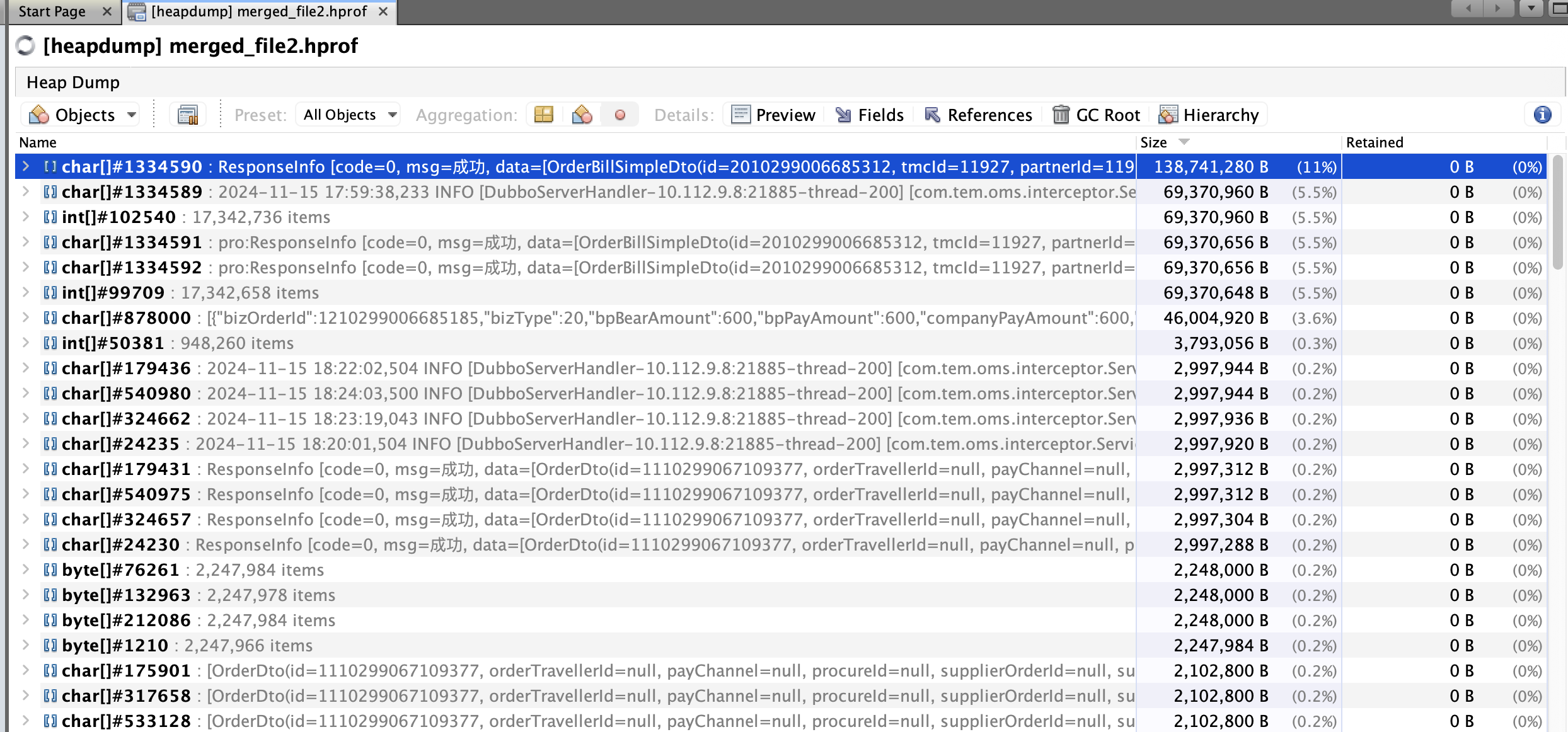
1 | 重点在R,e,s,p,o,n,s,e,I,n,f,o, ,[,c,o,d,e,=,0,,, ,m,s,g,=,成,功,,, ,d,a,t,a,=,[,O,r,d,e,r,B,i,l,l,S,i,m,p,l,e,D,t,o, |
Q7: ResponseInfo是找不到的,但是OrderBillSimpleDto可以找到,将所有的返回OrderBillSimpleDto 均加上数量集日志,发现如下,某个返回的列表竟然有近10w的数据 ,
Q8. 什么场景下需要查询10w的数据呢?
通过链路追踪,发现错误传参导致,condition传入了id,但是在service层接收的参数是orderId,所以导致会查询出所有的数据,所以第一这个地方要改正,其次service 层要加控制,最少要传入pageStart 和pageSize
一些思考和目前仍然没有答案的疑问
- 为了避免类似的情况发生,系统应该有大对象监控
- 为什么通过分析支配树分析无效
- 为什么打印出的日志是 ResponseInfo 且业务逻辑中没有使用到该类